How to know your WAS version is 32 bit or 64 bit?
This is a machine which has WAS 64 bit
$ ./java -d64 -version
java version "1.5.0_06"
Java(TM) 2 Runtime Environment, Standard Edition (IBM build 1.5.0_06-erdist-20060404 20060511)
Java HotSpot(TM) 64-Bit Server VM (build 1.5.0_06-erdist-20060404, mixed mode)
IBM Java ORB build orb50-20060511a (SR2)
XML build XSLT4J Java 2.7.4
XML build IBM JAXP 1.3.5
XML build XML4J 4.4.5
This is a machine which has WAS 32bit
$ ./java -d64 -version
execv(): No such file or directory
Error trying to exec /software/opt/IBM/WebSphere/AppServer/java/jre/bin/sparcv9/java.
Check if file exists and permissions are set correctly.
Failed to start a 64-bit JVM process from a 32-bit JVM.
Verify all necessary J2SE components have been installed.
(Solaris SPARC 64-bit components must be installed after 32-bit components.)
So acid Test is -
goto App Server javahome
/path/to/washome/java/jre/bin
./java -d64 -version
if it is 64 bit, it returns with version info.
otherwise returns with no such file or directory.
Tuesday, February 7, 2012
WebSphere Admin Tips
WebSphere Password Decoder
This utility can decode WebSphere encoded passwords.
If you have lost your password(s), use this utility to recover them.
url: http://www.sysman.nl/wasdecoder/
This utility can decode WebSphere encoded passwords.
If you have lost your password(s), use this utility to recover them.
url: http://www.sysman.nl/wasdecoder/
Run Websphere on other user than root
For his installation Websphere need to use root account. The installation's script don't propose the creation or utilisation of an other user account. This is disturbing because all the objets created by Webphere belong to root.
But it's easy to correct this problem.
Modifications to do
I take in account that you have created the user and the group that you wanted. After that you just have to connect yourself to the Websphere's administration console to change some parametres in this page : Execution process parameters.
You can go to this page thanks to the menu Servers > Applications server > name_of_your_server and (in the options of this page) Server Infrastructure > Gestion des processus and Java > Processus Execution.
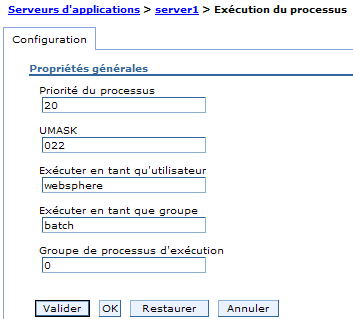
So you can change the user and group wich is going to run the principal process of Websphere ( java ). With that, all objects created by websphere (images, files, …) are accessible even to other user than root.
Warning : after this you must change the owner of all files and directorys read by Websphere ( $WAS_HOME/ and your WebApp and all other required files)
SSL(Secure Socket Layer)
What is SSL?
SSL is a protocol that provides privacy and integrity between two communicating applications using TCP/IP. The data going back and forth between client and server is encrypted using a symmetric algorithm.
A public-key algorithm (RSA) is used for the exchange of the encryption keys and for digital signatures. Public key cryptography defines an algorithm that uses two keys, each of which may be used to encrypt a message. If one key is used to encrypt a message, the other must be used to decrypt it. This makes it possible to receive secure messages by simply publishing one key (the public key) and keeping the other undisclosed (the private key).
Fig: Client/server authentication

- The SSL implementation used by the WebSphere® Application Server stores personal certificates in an SSL key file and signer certificates in a trust file.
- A key file contains a collection of certificates, each one of which may be presented during an SSL connection initiation in order to prove identity.
- A trust file contains a collection of certificates that are considered trustworthy and against which the presented certificate will be matched during an SSL connection initiation in order to assure identity.
- A key store contains the personal certificates that can be used as the identity for the SSL end point referencing the key store. If more than one certificate is present, a certificate alias on the SSL configuration specifies one of the personal certificates. When an SSL connection is made (on either the client or the server side), certificates may be exchanged. The personal certificate referenced by the SSL configuration and stored in the key store is the certificate that will be used.
- A personal certificate represents the identity of the end point and contains a public and private key for signing/encrypting data.
- A trust store contains the signer certificates which this end point trusts when either making connections (from an outbound end point) or accepting connections (for an inbound end point).
- A signer certificate represents a certificate and public key associated with some personal certificate. The purpose of the signer certificate is to verify personal certificates. By accepting the signer certificate into an end point's trust store, you are allowing the owner of the private key to establish connections with this end point; that is, the signer certificate explicitly trusts connections made to or by the owner of the associated personal certificate. The signer certificate is typically made completely public by the owner of the personal certificate, but it's up to the receiving entity to determine if it is a trusted signer prior to adding it to the trust store.
Data encryption to prevent the exposure of sensitive information while data flows across the wire.
Data signing to prevent unauthorized modification of data while data flows across the wire.
Client and server authentication to ensure that you talk to the appropriate person or machine.
SSL provides secure communications between the Internet web client and the Administrative server.
You must have a digital certificate, keystore file, and truststore file to fully implement SSL communications key store file is used to setup secure MQ channels to the message flow servertruststore: set SSl security for the websphere application server
digital certificates are issued by trusted parties called certificate authoritiesYou can create self signed certificate if you do not have a certificate issued by a CADigital certificate
A digital certificate reveals information about its owner, including their identity. During the initialization of an SSL connection, the server must present its certificate to the client for the client to determine the server identity.
Keystore file
The keystore file is a key database file that contains both public keys and private keys. Public keys are stored as signer certificates while private keys are stored in the personal certificates. The keys are used for a variety of purposes, including authentication and data integrity. You can use both the key management utility (iKeyman) and the keytool utility to create.
Truststore file
A truststore file is a key database file that contains the public keys for target servers. The public key is stored as a signer certificate. If the target uses a self-signed certificate, extract the public certificate from the server keystore file. Add the extracted certificate into the truststore file as a signer certificate. For a commercial certificate authority (CA), the CA root certificate is added. The truststore file can be a more publicly accessible key database file that contains all the trusted certificates.
Start the IBM Key Management application c:\Program Files\IBM\gsk7\bin\gsk7ikm.exeNote: The JAVA_HOME variable must be set. The default location is C:\Program Files\WebSphere\AppServer\java.
For example:
set JAVA_HOME=C:\Program Files\WebSphere\AppServer\java
To Create a key file and self-signed certificate:
Select KeyDatabaseFile > New and enter the followingSelect KeyDatabaseFile > New and enter the following:
Table 1. KeyDatabaseFile values File Name HCNAdminServerKeyFile.jks Location WAS_HOME\etc\
Click OK.
Enter the Key File Password as defined in Table 1 table.
Click OK.
Under Key database content select Personal Certificates.
Click New self-signed.
Enter the following:
Table 2. Administrative server Key file properties Propery Value
Key Label HCN Admin
Common Name Administrative server host name
Example: hcnadmin.ibm.com
Organization Enter an organization name.
Validity Period Enter 7300 days, this is the maximum.
Country or Region Change if default not appropriate.
Create Trust File HCNAdminServerTrustFile.jks using the same values as in step 2. Place HCNAdminServerTrustFile.jks in WAS_HOME\etc.
Start IBM WebSphere Application Server Base V5.1.1 Administration Console.
Click Security > SSL > New Enter the following values:
Table 1. SSL Values Property Value
Alias HCNAdminSSLSettings Key File Name ${USER_INSTALL_ROOT}/etc/HCNAdminServerKeyFile.jks
Key File Password password
Trust File Name ${USER_INSTALL_ROOT}/etc/HCNAdminServerTrustFile.jks
Trust File Password password
${USER_INSTALL_ROOT} expands to the WebSphere Application Server installation path on your machine. It is defined in the IBM WebSphere Application Server Administrative Console.
Click OK
Click Servers > Application Servers > server1 > Web Container > HTTP Transports
Click * next to SSL port 443
Select the ADMIN_SERVER_NAME/HCNAdminSSLSettings.
Click OK > Save > Save.
Restart WebSphere.
Test the Administrative server main page (https://ADMIN_SERVER_NAME/hcn/index.html).
You must have a digital certificate, keystore file, and truststore file to fully implement SSL communications key store file is used to setup secure MQ channels to the message flow servertruststore: set SSl security for the websphere application server
digital certificates are issued by trusted parties called certificate authoritiesYou can create self signed certificate if you do not have a certificate issued by a CADigital certificate
A digital certificate reveals information about its owner, including their identity. During the initialization of an SSL connection, the server must present its certificate to the client for the client to determine the server identity.
Keystore file
The keystore file is a key database file that contains both public keys and private keys. Public keys are stored as signer certificates while private keys are stored in the personal certificates. The keys are used for a variety of purposes, including authentication and data integrity. You can use both the key management utility (iKeyman) and the keytool utility to create.
Truststore file
A truststore file is a key database file that contains the public keys for target servers. The public key is stored as a signer certificate. If the target uses a self-signed certificate, extract the public certificate from the server keystore file. Add the extracted certificate into the truststore file as a signer certificate. For a commercial certificate authority (CA), the CA root certificate is added. The truststore file can be a more publicly accessible key database file that contains all the trusted certificates.
Start the IBM Key Management application c:\Program Files\IBM\gsk7\bin\gsk7ikm.exeNote: The JAVA_HOME variable must be set. The default location is C:\Program Files\WebSphere\AppServer\java.
For example:
set JAVA_HOME=C:\Program Files\WebSphere\AppServer\java
To Create a key file and self-signed certificate:
Select KeyDatabaseFile > New and enter the followingSelect KeyDatabaseFile > New and enter the following:
Table 1. KeyDatabaseFile values File Name HCNAdminServerKeyFile.jks Location WAS_HOME\etc\
Click OK.
Enter the Key File Password as defined in Table 1 table.
Click OK.
Under Key database content select Personal Certificates.
Click New self-signed.
Enter the following:
Table 2. Administrative server Key file properties Propery Value
Key Label HCN Admin
Common Name Administrative server host name
Example: hcnadmin.ibm.com
Organization Enter an organization name.
Validity Period Enter 7300 days, this is the maximum.
Country or Region Change if default not appropriate.
Create Trust File HCNAdminServerTrustFile.jks using the same values as in step 2. Place HCNAdminServerTrustFile.jks in WAS_HOME\etc.
Start IBM WebSphere Application Server Base V5.1.1 Administration Console.
Click Security > SSL > New Enter the following values:
Table 1. SSL Values Property Value
Alias HCNAdminSSLSettings Key File Name ${USER_INSTALL_ROOT}/etc/HCNAdminServerKeyFile.jks
Key File Password password
Trust File Name ${USER_INSTALL_ROOT}/etc/HCNAdminServerTrustFile.jks
Trust File Password password
${USER_INSTALL_ROOT} expands to the WebSphere Application Server installation path on your machine. It is defined in the IBM WebSphere Application Server Administrative Console.
Click OK
Click Servers > Application Servers > server1 > Web Container > HTTP Transports
Click * next to SSL port 443
Select the ADMIN_SERVER_NAME/HCNAdminSSLSettings.
Click OK > Save > Save.
Restart WebSphere.
Test the Administrative server main page (https://ADMIN_SERVER_NAME/hcn/index.html).
SSL(Secure Socket Layer)
What is SSL?
SSL is a protocol that provides privacy and integrity between two communicating applications using TCP/IP. The data going back and forth between client and server is encrypted using a symmetric algorithm.
A public-key algorithm (RSA) is used for the exchange of the encryption keys and for digital signatures. Public key cryptography defines an algorithm that uses two keys, each of which may be used to encrypt a message. If one key is used to encrypt a message, the other must be used to decrypt it. This makes it possible to receive secure messages by simply publishing one key (the public key) and keeping the other undisclosed (the private key).
Fig: Client/server authentication

Data encryption to prevent the exposure of sensitive information while data flows across the wire.
Data signing to prevent unauthorized modification of data while data flows across the wire.
Client and server authentication to ensure that you talk to the appropriate person or machine.
SSL is a protocol that provides privacy and integrity between two communicating applications using TCP/IP. The data going back and forth between client and server is encrypted using a symmetric algorithm.
A public-key algorithm (RSA) is used for the exchange of the encryption keys and for digital signatures. Public key cryptography defines an algorithm that uses two keys, each of which may be used to encrypt a message. If one key is used to encrypt a message, the other must be used to decrypt it. This makes it possible to receive secure messages by simply publishing one key (the public key) and keeping the other undisclosed (the private key).
Fig: Client/server authentication
- The SSL implementation used by the WebSphere® Application Server stores personal certificates in an SSL key file and signer certificates in a trust file.
- A key file contains a collection of certificates, each one of which may be presented during an SSL connection initiation in order to prove identity.
- A trust file contains a collection of certificates that are considered trustworthy and against which the presented certificate will be matched during an SSL connection initiation in order to assure identity.
- A key store contains the personal certificates that can be used as the identity for the SSL end point referencing the key store. If more than one certificate is present, a certificate alias on the SSL configuration specifies one of the personal certificates. When an SSL connection is made (on either the client or the server side), certificates may be exchanged. The personal certificate referenced by the SSL configuration and stored in the key store is the certificate that will be used.
- A personal certificate represents the identity of the end point and contains a public and private key for signing/encrypting data.
- A trust store contains the signer certificates which this end point trusts when either making connections (from an outbound end point) or accepting connections (for an inbound end point).
- A signer certificate represents a certificate and public key associated with some personal certificate. The purpose of the signer certificate is to verify personal certificates. By accepting the signer certificate into an end point's trust store, you are allowing the owner of the private key to establish connections with this end point; that is, the signer certificate explicitly trusts connections made to or by the owner of the associated personal certificate. The signer certificate is typically made completely public by the owner of the personal certificate, but it's up to the receiving entity to determine if it is a trusted signer prior to adding it to the trust store.
Data encryption to prevent the exposure of sensitive information while data flows across the wire.
Data signing to prevent unauthorized modification of data while data flows across the wire.
Client and server authentication to ensure that you talk to the appropriate person or machine.
Webserver errors
Webserver errors
Errors on the Internet, and those annoying error messages, occur quite frequently -- and can be quite frustrating, especially if you do not know the difference between a 404 error and a 502 error. Many times they have more to do with the Web servers you're trying to access rather than something being wrong with your computer. Here is a list of error messages you might encounter while surfing the Web and their respective meanings to help you figure out just what the problem is.
| 400 Bad File Request | Usually means the syntax used in the URL is incorrect (e.g., uppercase letter should be lowercase letter; wrong punctuation marks). |
| 401 Unauthorized | Server is looking for some encryption key from the client and is not getting it. Also, wrong password may have been entered. Try it again, paying close attention to case sensitivity. |
| 403 Forbidden/Access Denied | Similar to 401; special permission needed to access the site -- a password and/or username if it is a registration issue. Other times you may not have the proper permissions set up on the server or the site's administrator just doesn't want you to be able to access the site. |
| 404 File Not Found | Server cannot find the file you requested. File has either been moved or deleted, or you entered the wrong URL or document name. Look at the URL. If a word looks misspelled, then correct it and try it again. If that doesn't work backtrack by deleting information between each backslash, until you come to a page on that site that isn't a 404. From there you may be able to find the page you're looking for. |
| 408 Request Timeout | Client stopped the request before the server finished retrieving it. A user will either hit the stop button, close the browser, or click on a link before the page loads. Usually occurs when servers are slow or file sizes are large. |
| 500 Internal Error | Couldn't retrieve the HTML document because of server-configuration problems. Contact site administrator. |
| 501 Not Implemented | Web server doesn't support a requested feature. |
| 502 Service Temporarily Overloaded | Server congestion; too many connections; high traffic. Keep trying until the page loads. |
| 503 Service Unavailable | Server busy, site may have moved ,or you lost your dial-up Internet connection. |
| Connection Refused by Host | Either you do not have permission to access the site or your password is incorrect. |
| File Contains No Data | Page is there but is not showing anything. Error occurs in the document. Attributed to bad table formatting, or stripped header information. |
| Bad File Request | Browser may not support the form or other coding you're trying to access. |
| Failed DNS Lookup | The Domain Name Server can't translate your domain request into a valid Internet address. Server may be busy or down, or incorrect URL was entered. |
| Host Unavailable | Host server down. Hit reload or go to the site later. |
| Unable to Locate Host | Host server is down, Internet connection is lost, or URL typed incorrectly. |
| Network Connection Refused by the Server | The Web server is busy. |
JDBC Driver in Websphere
Why Drivers Matter
Why Drivers Matter
A JDBC driver can make a world of difference in how well your application performs. Features supported by your JDBC driver are in fact critical to system performance. This is particularly true in enterprise database applications, and more so in applications accessing distributed data sources.
Many database products ship with their own JDBC drivers. So why should you purchase a separate driver when you already may get one free in your DBMS? There are several reasons. First, the handful of vendors who actually develop these drivers (most database vendors license their drivers) can offer you better support for their drivers than the database vendors can offer for drivers they only license. This is not surprising: Creating commercial-quality drivers is hard work. The driver creator would be expected to know the driver details better than anyone else—Driver design is what they do.
Many developers don't realize that their JDBC driver can be a performance bottleneck for their application because of issues like connection handling. They are pleasantly surprised, for example, when they upgrade their native database JDBC driver to a Type 3 or Type 4 JDBC product from a dedicated driver vendor. Many companies make major purchases of a JDBC driver vendor's product even when a version of that product is part of the DBMS that they already own.
As you look to the future, consider the features that JDBC 3.0 provides as a marker in deciding which driver to consider, including DataSource objects, connection pooling, distributed transaction support, RowSets, and prepared statement pooling. When possible, choose a vendor whose drivers work directly with database vendors APIs, and not drivers that have been reversed engineered to work with those APIs. The former type is typically a faster performer.
Type 3 and Type 4 drivers are the drivers to use when performance and compliance with Java standards is a must. It's extremely worthwhile to find a vendor whose drivers support the very latest versions of JDBC and the widest array of JDBC features. Another factor to consider is that different JDBC drivers offer tools that don't normally come with native DBMS drivers—tools that can be quite important in your development work.
JDBC Driver Types
JDBC drivers are divided into four types or levels. The different types of jdbc drivers are:
Type 1: JDBC-ODBC Bridge driver (Bridge)Type 2: Native-API/partly Java driver (Native)
Type 3: AllJava/Net-protocol driver (Middleware)
Type 4: All Java/Native-protocol driver (Pure)
4 types of jdbc drivers are elaborated in detail as shown below:
Type 1 JDBC Driver
JDBC-ODBC Bridge driver
The Type 1 driver translates all JDBC calls into ODBC calls and sends them to the ODBC driver. ODBC is a generic API. The JDBC-ODBC Bridge driver is recommended only for experimental use or when no other alternative is available.

Type 1: JDBC-ODBC Bridge
Advantage
The JDBC-ODBC Bridge allows access to almost any database, since the database's ODBC drivers are already available.
Disadvantages
1. Since the Bridge driver is not written fully in Java, Type 1 drivers are not portable.
2. A performance issue is seen as a JDBC call goes through the bridge to the ODBC driver, then to the database, and this applies even in the reverse process. They are the slowest of all driver types.
3. The client system requires the ODBC Installation to use the driver.
4. Not good for the Web.
Type 2 JDBC Driver
Native-API/partly Java driver
The distinctive characteristic of type 2 jdbc drivers are that Type 2 drivers convert JDBC calls into database-specific calls i.e. this driver is specific to a particular database. Some distinctive characteristic of type 2 jdbc drivers are shown below. Example: Oracle will have oracle native api.

Type 2: Native api/ Partly Java Driver
Advantage
The distinctive characteristic of type 2 jdbc drivers are that they are typically offer better performance than the JDBC-ODBC Bridge as the layers of communication (tiers) are less than that of Type1 and also it uses Native api which is Database specific.
Disadvantage
1. Native API must be installed in the Client System and hence type 2 drivers cannot be used for the Internet.
2. Like Type 1 drivers, it's not written in Java Language which forms a portability issue.
3. If we change the Database we have to change the native api as it is specific to a database
4. Mostly obsolete now
5. Usually not thread safe.
Type 3 JDBC Driver
All Java/Net-protocol driver
Type 3 database requests are passed through the network to the middle-tier server. The middle-tier then translates the request to the database. If the middle-tier server can in turn use Type1, Type 2 or Type 4 drivers.

Type 3: All Java/ Net-Protocol Driver
Advantage
1. This driver is server-based, so there is no need for any vendor database library to be present on client machines.
2. This driver is fully written in Java and hence Portable. It is suitable for the web.
3. There are many opportunities to optimize portability, performance, and scalability.
4. The net protocol can be designed to make the client JDBC driver very small and fast to load.
5. The type 3 driver typically provides support for features such as caching (connections, query results, and so on), load balancing, and advanced
system administration such as logging and auditing.
6. This driver is very flexible allows access to multiple databases using one driver.
7. They are the most efficient amongst all driver types.
Disadvantage
It requires another server application to install and maintain. Traversing the recordset may take longer, since the data comes through the backend server.
Type 4 JDBC Driver
Native-protocol/all-Java driver
The Type 4 uses java networking libraries to communicate directly with the database server.
Type 4: Native-protocol/all-Java driver
Advantage
1. The major benefit of using a type 4 jdbc drivers are that they are completely written in Java to achieve platform independence and eliminate deployment administration issues. It is most suitable for the web.
2. Number of translation layers is very less i.e. type 4 JDBC drivers don't have to translate database requests to ODBC or a native connectivity interface or to pass the request on to another server, performance is typically quite good.
3. You don't need to install special software on the client or server. Further, these drivers can be downloaded dynamically.
Disadvantage
With type 4 drivers, the user needs a different driver for each database.
-------------------------------------------------------------------------------------------------------------------------------
The JDBC Specification
Now let's take a look at the specifics. JDBC has gone through several major version releases:
- JDBC 1.0 was designed to provide basic functionality with an emphasis on ease of use.
- JDBC 2.0 offered more advanced features and server-side capabilities.
- JDBC 3.0 "rounded out" the API by providing performance optimization. It added improvements in the areas of connection pooling, statement pooling, and provided a migration path to Sun Microsystems' connector architecture.
The optional features in JDBC 2.0 (such as connection and distributed transactions) are now required features in JDBC 3.0, along with the new features in JDBC 3.0, such as prepared statement pooling.
JDBC Driver Types—Know the DifferenceDatabase access by Java applications wasn't part of the original Java specification. It didn't take long for Sun Microsystems and other vendors to fill the gap. Early data-access Java methods relied on bridging the Microsoft-sponsored ODBC (Open Database Connectivity) standard for access to data sources, resulting in the JDBC-ODBC bridge drivers.
Today, there are four types of JDBC drivers in use:
- Type 1: JDBC-ODBC bridge, plus an ODBC driver
- Type 2: native API, part-Java driver
- Type 3: pure Java driver for database middleware
- Type 4: pure Java driver for direct-to-database
Type 3 and Type 4 JDBC drivers are both pure Java drivers, and therefore, offer the best performance, portability, and range of features for Java developers.
Type 1
A Type 1 JDBC driver is a JDBC-ODBC Bridge, plus an ODBC driver. Sun Microsystems recommends using Type 1 drivers for prototyping only and not for production purposes. The bridge driver is provided by Sun without support to developers and is intended to support legacy products. When a major patch is required, Sun provides it, but they do not provide end-user support for this software. Typically, the bridge is used when there is already an investment in ODBC technology, such as in Windows application servers.
Sun Microsystems provides a JDBC-ODBC Bridge driver, but because ODBC loads binary code and database client code on the client using the bridge, this technology isn't suitable for a high-transaction environment. Type 1 drivers also don't support the complete Java command set and are limited by the functionality of the ODBC driver.
Type 2
A Type 2 JDBC driver is a native-API, part-Java driver. Type 2 drivers are used to convert JDBC calls into native calls of the major database vendor APIs. These drivers suffer from the same performance issues as Type 1 drivers, namely binary-code client loading, and they are platform-specific.
Type 2 drivers force developers to write platform-specific code, something no Java developer really wants to do. But, because large database vendors, such as Oracle and IBM, use Type 2 drivers for their enterprise databases, developers who use these drivers must keep up with different driver releases for each database vendor's product release and each operating system.
Also, because Type 2 drivers don't use the full Java API, developers find themselves having to perform additional configuration when connecting Java applications to data sources. Often, Type 2 drivers aren't architecturally compatible with mainframe data sources, and when they are, they are less than ideal.
For these reasons and others, most Java database developers opt for either Type 3 or the newer and more flexible Type 4 pure Java JDBC drivers.
 |
Figure 1. The Architectural Difference Between Type 1 and Type 2 Drivers. While Type 1 JDBC drivers offer convenience of access to ODBC data sources, they are limited in their functionality and performance. Type 2 JDBC drivers are OS-specific and compiled, and although they offer more Java functionality and higher performance than Type 1 drivers, still require a controlled environment.Figure courtesy of Sun Microsystems. |
Type 3
Type 3 JDBC drivers are pure Java drivers for database middleware. JDBC calls are translated into a middleware vendor's protocol, and the middleware converts those calls into a database's API. Type 3 JDBC drivers offer the advantage of being server-based, meaning that they do not require native client code, which makes Type 3 drivers faster than Type 1 and Type 2 drivers. Developers can also use a single JDBC driver to connect to multiple databases.
Type 4
Type 4 JDBC drivers are direct-to-database pure Java drivers ("thin" drivers). A Type 4 driver takes JDBC calls and translates them into the network protocol (proprietary protocol) used directly by the DBMS. Thus, client machines or application servers can make direct calls to the DBMS server. Each DBMS requires its own Type 4 driver; therefore, there are more drivers to manage in a heterogeneous computing environment, but this is outweighed by the fact that Type 4 drivers provide faster performance and direct access to DBMS features.
 |
Figure 2. The architectural difference between Type 3 and Type 4 drivers. Type 3 drivers leverage the advantages of middleware products to supply heterogeneous database access, and are a strong server-side solution when that middleware product runs on a single OS. Type 4 drivers provide fast and powerful direct access from Java clients to the databases themselves, but do not provide some of the server-side OS optimization found in Type 3 drivers. Figure courtesy of: Sun Microsystems. |
Sun Microsystems maintains a listing of JDBC drivers at:http://industry.java.sun.com/products/jdbc/drivers, shown in Figure 3. This web page offers a driver selector tool that allows you to generate a list of drivers that support specific features, including driver types, JDBC version support, and access to one or multiple specific databases. As of the writing of this article (March 2002) there were 155 drivers listed on this page!
Note: The driver selector tool shown in Figure 3 hasn't yet been updated to account for JDBC version 3.0, so expect to see some changes in this tool in the months to come. What you see in Figure 3 might not match what is on the Sun Microsystems web page at a later date.
Let's consider the feature choices listed on the Sun Microsystems JDBC driver web page in a little detail, because, as we said, many people use this tool to select one driver over another:
- JDBC API version number (Any, 1.x or 2.x (select one)).
- Certified for J2EE: J2EE 1.3 or J2EE 1.2 (select any or all).
- Driver Type: 1, 2, 3, 4, All, or Any (select any or all).
- Supported DBMS. There are 83 choices, mostly vendor products, but a few of which are industry standards like JDBC, LDAP, ODBC, OLE DB Provider, Text (TSV), SQL/DS, and XML. One or a group of selections are supported.
- Required Features: DataSource, Connection Pooling, Distributed Transactions, and RowSets (pick any or all).
- Returns per page (specifies the number of matches returned).
 |
Figure 3. Sun's JDBC Driver home page offers a selection tool that helps a developer select a driver based on its type and a number of other factors. |
Let's take a look at each feature in turn, and see if we can make sense out of each feature and their options.
JDBC API
The JDBC API is important because it determines the Java functionality available to a developer. While older Java applications may not be able to take advantage of the more advanced features provided by JDBC 3.0, any high-transaction, distributed application certainly would. What developers get when they use later versions of the API is any new DBMS and operating-system security enhancements, and the latest performance improvements such as advancements in connection pooling, statement pooling, RowSet objects, and so forth.
Certification
Remember that JDBC is a specification, and not a standardized piece of software. Vendors are free to implement their JDBC drivers to that specification as they see fit, and while some JDBC drivers are fully J2EE compliant; many other drivers are not. When considering one driver over another, the Certified for J2EE logo, as specified by the Sun Certification Test Suite (CTS) and administered by Key Labs, is one yardstick a company can use to measure a driver's quality. Any company who undertakes the certification process is more likely to pay attention to quality control in their product. You will find a listing of vendors who have endorsed the JDBC standard and have products in this area at:http://java.sun.com/products/jdbc/industry.html.
Required Features
The "Required Features" section shown in Figure 3 lists some features, introduced in JDBC 2.0, but required for JDBC version 3.0.
A DataSource is an object containing the connection information to a database that is managed by a JDBC driver. Data sources work with a JNDI (the Java Naming Directory Interface) service, and a connection is instantiated and managed independently of the applications that use it. Connection information, such as path and port number, can be quickly changed in the properties of the DataSource object without requiring code changes in the applications that use the data source. Currently 50 of the 155 listings (not all are drivers) on the Sun Microsystems web page support this feature.
JDBC supports connection pooling, which essentially involves keeping open a cache of database connection objects and making them available for immediate use for any application that requests a connection. Instead of performing expensive network roundtrips to the database server, a connection attempt results in the re-assignment of a connection from the local cache to the application. When the application disconnects, the physical tie to the database server is not severed, but instead, the connection is placed back into the cache for immediate re-use, substantially improving data access performance.
Opening a connection is the most resource-expensive step in database transactions. When an application creates a connection, multiple separate network roundtrips must be performed to establish that connection (for an Oracle connection, that number is nine). However, once the connection object has been created, there is little penalty in leaving the connection object in place and reusing it for future connections. This feature offers significant potential to improve data transfer performance and scalability, especially for application servers. This feature is supported by 50 of the listings on the Sun Microsystems web page.
In a distributed system, applications often must retrieve data using multiple transactions, and often from multiple data sources. Any transaction that requires the coordination of independent cooperating transactional systems is referred to as a distributed transaction. Aside from the performance characteristics of JDBC drivers, distributed transaction support is probably the most requested feature by Java database developers.
Distributed transactions require additional resources to be reliably supported, primarily because of the differences in latencies when retrieving data from different data sources, and because of interoperability issues. For example, a failed transaction is not easily differentiated from a slow transaction, requiring resource managers in a DTS be both registered and coordinated to handle ROLLBACK or COMMIT operations correctly without a lot of code development.
Typically, distributed transactions use a transaction manager to provide the coordination that the different resource managers need. With a transaction manager in a Distributed Transaction Processing (DTP) architecture providing the mediation between applications and resources, it's possible to provide applications with ACID transactions across multiple data sources.
In a situation where multiple steps are required to produce the desired result, there needs to be a software module, which is often a transaction manager, coordinating the process. A product like iPlanet Trustbase Transaction Manager is one example of this type of software. It's used in global banking and B2B systems to provide the services required to secure processing and routing based on a key structure, and includes cryptographic support and identity checking. Only 34 of the drivers on the Sun Microsystems JDBC driver web page offer this feature.
A RowSets object is the result set of a query containing rows from a tabular data source. RowSets have properties and event notification similar to JavaBeans and are a JavaBean component that can be created and used programmatically in a development tool. There are connected anddisconnected rowsets. Disconnected rowsets are connected to a data source that is populated and do not require a JDBC driver when disconnected. These types of rowsets are small, and often are used to send data to a thin client. Disconnected rowsets are stored in memory along with their metadata and connection and execution instructions. A connected rowset maintains an open connection while the rowset is being used. Only 18 of the drivers now listed support the rowsets feature, which as this small number suggests, isn't an often used feature.
A note worth mentioning: On the Sun JDBC Driver site, Sun defines "support" for RowSets to mean actually packaging and shipping the RowSets with the JDBC driver. Thus, you will find that there are drivers on this site that, while not showing a check mark next to "RowSets," in fact do support multiple types of RowSets.
Not on the current list, but sure to be added as a searchable feature because it's in JDBC version 3.0, is a feature called prepared statement pooling. Essentially, statement pooling caches SQL queries that have been previously optimized and run so that, should they be needed again, they do not have to go through optimization pre-processing again. Statement pooling can be a significant performance booster and is something to look for in any JDBC driver.
Prepared statements are particularly valuable when the same SQL statement is executed many times. A query that populates the current status of a particular category of inventory, run many times during the day, would be one example. To execute the statement a second time, only the values of the statement's parameters need to be passed to it. All the optimization steps, such as checking syntax, validating addresses, and optimizing access paths and execution plans, are already cached in memory. Statement caching is a JDBC driver feature.
What's even better from a developer's standpoint is that statement pooling operates without a developer having to code for it (as does connection pooling). You get the performance enhancement when you buy a driver that supports this feature.
Statement pooling and connection pooling can work together in your applications, as long as your driver supports them. When a J2EE Enterprise JavaBean and session bean makes use of a connection from the connection pool, any connection that was previously used to run a SQL statement will have its statement pool already defined. Therefore, even the application's first attempt to prepare a statement for a particular connection will not require the statement preparation process. Statement pooling can be used on any connection, regardless of whether the connection came from a non-pooled data source, or from an application server that uses a pooled data source or a JDBC driver's connection pool.
Subscribe to:
Posts (Atom)